交叉统计是什么统计方式?请具体告诉我统计表的制作方法和阅读方法。
Answer
交叉统计就是从所给数据中提取两个以上的关注项目,把各项目放在表的列和行上进行统计的方法。交叉统计的目的是为了获得简单统计中掌握不了的属性或者问题之间的深层洞察。
解起
■什么是交叉统计?
在调查中,对回答某个问题的人或者数据库中存在的数据次数和比例,用单个项目的观点进行统计的,叫做“简单统计”。与此相对,“交叉统计”是指在表头和表格侧部写入了属性项目或者问题项目,进行项目次数和比例的复杂统计。简单统计只能统计问卷调查中的性别或地区等基础的项目,而通过交叉统计,可以知道与属性栏相关的问题等,从而获得更加深刻的认知。
交叉统计可用表格计算软件进行简单的制作。最常见的表格计算软件是Microsoft的Excel,利用“数据透视表(PivotTable)"功能,通过在表格的顶部、侧部的自由插入,就可以更改数据的统计方法。
■交叉统计表的读取方法
通过交叉统计表,可以读取项目之间的关联性。如果各项目之间的某处存在较大差异,就说明那里有某些潜在原因。这个差异是营销

策略实施的重要依据,所以从交叉统计表中读出差异非常重要。要判断有无差异,正确检验的统计技术是必需的,此外,能够正确理解并利用检验也很重要。在这里我们向大家介绍一种简单易懂的找到差异的方法。
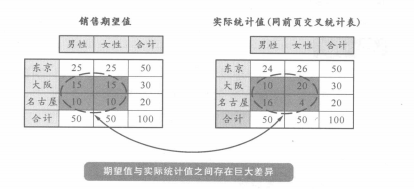
这种方法就是找出期望值和统计值差距很大的栏目。这里说的期望值是指在进行简单统计时得出的和各项目之间完全没有关联的统计数值。例如:在上图的简单统计表和交叉统计表中,可知东京的男女人数合计为50。在简单统计表里,男女比例是1:1,那么在交叉统计表中,男女比例的期望值也就是1:1,东京合计的50人当中,男女应该各为25人。再看一下交叉统计表中的实际统计值,是男24人,女26人,这样我们就知道,统计值和期望值没有多大差异。
在大阪和名古屋,通过同样的计算,发现期望值和实际统计值有很大的差异。名古屋女性这一栏尤为显著,期望值是10人,而实际统计值只有4人,这样我们就知道期望值是实际值的2.5倍。像这样有很大差异的项目内容,在评价和解释交叉统计表的时候就非常引人注目。负责分析的人员将把产生“这种差异”的原因也包括在内,对统计结果进伸价、分析。
■多重交叉统计的注意事项
初学交叉统计的人都很容易产生过度依赖。初学者为了更加深刻地洞察各项目,往往过多地使用3重、4重甚至更多重交叉表;但随着多重度的增多,每个栏里所能容纳的数据度数也会变少。如果每栏的数据度数比参数小很多的话,这个数值就会变得没有多少说服力,这一点希望大家注意。
Answer
所谓多变量解析就是统计分析多个变量的数据后,明确变量间的关系,发现有效信息的手法的总称。
■什么是多变量解析?
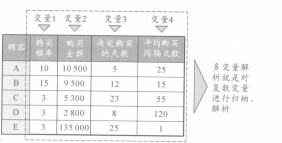
在了解多变量解析前,有必要先了解一下什么是变量。例如下面是某个店铺制作的关于每个顾客购物情况数据的表格。“购买频率”、“购买金额”等项目中,由于顾客不同对应的数据也不同。在统计学中,值随着样本(这里指顾客)变化而变化的项目就叫做变量(或者叫变数)。
所谓多变量解析,并不是把多个变量细分化,而是同时进行分析,然后得到有效的信息。
所谓多变量解析,并不是把多个变量细分化,而是同时进行分析,然后得到有效的信息。
■多变量解析的特征
既然有多变量解析,当然也就有一个变量或是两个变量的解析。我们把变量是一个的叫做“单变量解析”或者“一变量解析”,把变量是两个的叫做“二变量解析”。用一变量解析和二变量解析,可以通过查频率分布和散布图得到一些信息。这些方法非常简单,也比较容易理解,但另一方面因为变量太少,只能看到实物的一个或两个方面,得出的结果,一般没有什么意义。例如上文所列举的顾客数据,如果一个一个变量地看,购买频率最高的是A.购买金额最高的是E。只能得到这样的数据。
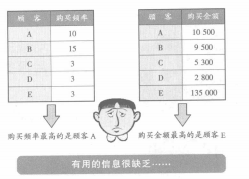
多变量解析则可以同时分析多个变量之间的关系,这样,我们就可以知道某个变量对其他变量有什么影响。例如通过多变量解析我们有可能找出研究对象的选定和研究时机的选定之间存在的关系。
运用多变量解析,专业的统计知识是必要的。以前,由于计算量庞大,要得到计算结果比较困难,但随着计算机的发展和多变量解析软件的改良,现在的企业和个人在运用多变量解析时已经容易多了。
根据多变量解析的分析目的和变量的种类不同,有很多种处理方法,所得到的结果也不同。如果没有正确的知识就去运用这些方法,会导致意想不到的错误,甚至可能只得到一些错误的答案。因此,利用多变量解析,正确理解各种方法很重要。
构建顾客行动模式,制作反应率高的名单,具体应该利用哪些数据,采取哪些步骤?
Answer
利用顾客属性、购买记录、过去的促销信息等构建顾客行动模式,以此模式为基础计算出各顾客的行动概率。
■制作名单的步骤
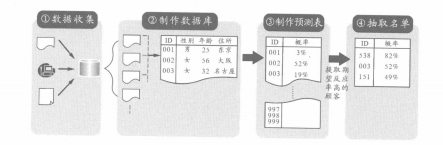
顾客行动模式是企业基于顾客属性、购买行为等过去的信息做成的、预测顾客将来行动方式的“数学公式”o以这个数学公式为基础,算出顾客(以及潜在顾客)的期望反应率,然后再抽取期望反应率高的顾客制作成电话外呼对象的顾客名单。大致来说,制作出期望反应率高的名单需要以下4个步骤:
①数据收集
首先,将企业内分散的数据汇集到一处。企业各操作现场获得的与顾客相关的所有信息都有可能成为构建顾客行动模式的原始数据o如注册积分卡时登记的性别、出生日期等顾客属性信息,记录了顾客在何时以何种价格购买了什么商品等的购买记录信息,发送电子杂志、直邮广告等方面的促销信息等,都可以作为原始数据。
②制作数据库
接着,把多个原始数据汇总到一张表上做成数据库。首先要设计使用哪个原始数据作为某列项目来制作数据库,然后进行数据清理、姓名汇总等,以一个顾客一条记录的汇集形式加以总结。在数据库的项目中,涵盖了从顾客属性到平均购买额、单位时间的购买次数、平均购买件数、购买间隔、直邮发送次数、直邮反应率(携带在直邮里的优惠券的使用率)等信息。制作数据库的具体情况,将在FAQ16中详细说明。
③制作预测表
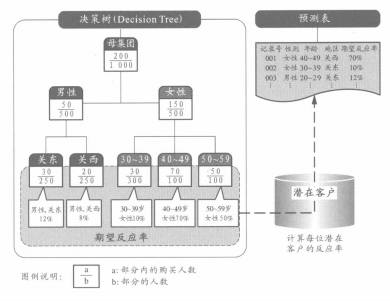
预测表是顾客将发生某种行动的概率(期望反应率)一览表。要制作预测表,需先使用统计的分析方法构建顾客行动模式,以该模式为基础,通过打分来算出每个顾客的期望反应率(预测值)。较容易理解的例子就是“决策树"(DecisionTree)。决策树是通过树形图来表示数据项目间的因果关系,同时计算出不同属性顾客的期望反应率。制作顾客行动模式时,一般运用市场上销售的数据挖掘软件,如Market Switch公司销售的“TrueforTransactionModeling(TTM)”等。
④抽取名单
从预测表中抽取行动概率高的顾客,制作反应率高的顾客名单。抽取的顾客数以业务规模、打电话费用等为基础来设定。
制作用于构建顾客行动模式的数据库,需要做哪些工作?
Answer
每个顾客都有一份档案,这就是用于构建顾客行动模式的数据。但其中一连串的处理不但复杂且繁琐,要花费很多时间。
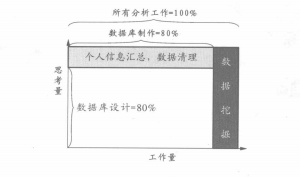
■数据库制作占整个分析工作量的80%
为了制作用于构建顾客行动模式的数据库,首先要明确其利用目的,在此基础上再进行设计工作;然后根据设计的内容进行数据清理及个人、家庭信息汇总等。
通过这样的一个过程,整理出一人一行的一览表,制成构建顾客行动模式可使用的数据库。这一系列处理会相当麻烦,因此需要花费很多时间。大体而言,数据库的制作要占到所有分析工作80%的工作量。
■数据库设计占整个数据库制作思考量的80%
数据库的设计是从已有的数据中,找出构建顾客行动模式所必需的信息。该数据库中的数据是顾客行动模式的输入数据,因此会直接影响模式的精度,所以数据库设计是所有分析工作中最重要的。要对数据进行细查,就应清楚地将能够使用的数据和不能够使用的数据分开。对于这项工作,不仅需要有缜密的思考能力,还要有在过去的经验及事物的基础上进行类推的能力。可以说在数据库的做成中数据库的设计就需要占用其80%的思考量(见下图)。
■需要的数据并不一定全部都有
数据库设计时,要找到构建顾客行动模式所必需的数据,但是想要的信息并不一定全都在自己公司的数据储备中。如果要制作精细的顾客行动模式,从顾客属性到对应的顾客履历,所有与顾客相关的数据都是需要的。但事实是,不要说收集所有的数据,就连收集到的数据也不一定完整。而且,收集到的数据也并不都可以直接用于顾客行动模式的构建。例如数据的分布范围过广,或者牵连的其他数据过多时,就难以得到正确的分析结果,或者无法充分把握其结果。
为了解决此类问题,需把收集到的数据进行适当加工,转换成对构建顾客行动模式有帮助的信息。例如,将邮政编码改为行政区域和地域名称,对购买履历中的购买次数、累计金额、间隔等变量做一个说明等。对于变量的说明需要经验和灵感,因此数据挖掘被公认为是一种“专业技能”。
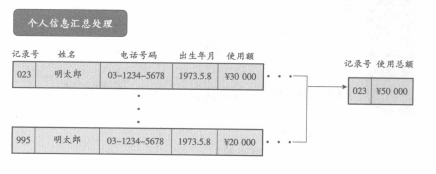
■数据库和个人信息汇总处理
即使作出了变量说明,也还没有完成构建顾客行动模式的数据库。还有必要进行数据清理和个人信息汇总。
数据清理是对信息内容进行大小写、全半角的统一,数据类型的统一,对空格(Null)等缺损值插入文字列实施处理,并用数据清理工具调整为可处理状态。如果一个项@的缺失信息太多,那么这个项目将从模式的构建内容中去除。
个人信息汇总是对数据库中存在的顾客信息进行统一化处理,把住所、姓名、电话号码、出生年月等作为关键项目,将同一顾客的多条记录汇总成一条记录。届时,再利用合算总额等方法,整合关键项目以外的信息。对于家庭,也存在统一化的必要,可以用同样的方法实行“家庭信息汇总”。
对在电话外呼的战略立案阶段中经常使用的几种分析方法,应该怎样选择?
分析方法的说明经营
Answer
根据不同的分析方法,导出的结果是不同的。因此,首先要做的事情是明确目的,然后再选择分析方法。
解说
■选择适合目的的分析方法
统计的分析方法各种各样,仅应用于营销的,就有50种左右。在这些方法中,选择一个适合的并非易事。根据不同目的,我们列举代表性的几种方法如下。

■几种分析方法的简要说明
①频率分布表(简单统计表)将数据分成几个组,对各个组数据的数量进行统计。这些组被称做“类别”,数据的数量被称做“频率”,可以用来把握整体数据的倾向。
②交叉统计表是用来把握不同属性间数值关系的方法。详见FAQ13。
③时序列分析根据每月获得客户数等的时序列,每经过一段时间,分析数据变化的方法。在时序列分析中,观测因时间变化而产生的数据趋向变化,根据得出的数字来预测将来。
④关联分析法分析顾客同时所购商品的方法。也称作“购物篮”(MarketBasket)分析法,是通过分析销售数据中的购买信息,找出交叉销售可能性较高的商品的分析方法。从分析结果来看,“尿布和啤酒”是很有名的例子。
⑤数群分析法是将整体性的数据分割成几个组的分析方法,也就是将有相似倾向的数据加以分类,进行使用。因为被分割的每一个组的数据都被称做“数群”,所以这个分析方法叫做数群分析法。
⑥判别分析法将存在的数据进行是非判断或者有无区分的分析方法。判定顾客会不会购买商品,是否是优质顾客等,总之是用来明确辨别是与否的分析法。
⑦决策树是将数据项目的因果关系用树状图形分类的分析法(详见FAQ15),”。因为是基于某种规则来分类的,所以能比较容易地理解被分类的优质顾客群或是预备解约顾客群所具有的特征。
周四和周五的傍晚,把“尿布和啤酒”放在一起卖?!
这是美国某个超级市场发生的事。事情是这样的,新上任的卖场负责人在观察消费者的行为时,感觉顾客好像把什么东西放在一起购买了,于是这位负责人把过去的销售记录也分析了一下。得出的结果怎样呢?竟然是啤酒和尿布两个都很畅销。当人们半信半疑地把啤酒和尿布摆放在一起时,的确是意想不到地卖得很好。特别是在周四和周五的傍晚,非常畅销。后来才知道,原来是妈妈们把买尿布的任务交给了下班回家的爸爸们,尤其是在周四和周五,这些爸爸们就会顺便把啤酒也买回来,准备周末喝。
对这件事的评价众说纷纭。“这是美国哪个超市的事啊,是真的吗?”实际上这是关联分析的著名事例,在营销界广为流传。在日本也有很多像“袜子和医疗保险一起卖”的例子,所以这并不是简单虚构的故事。