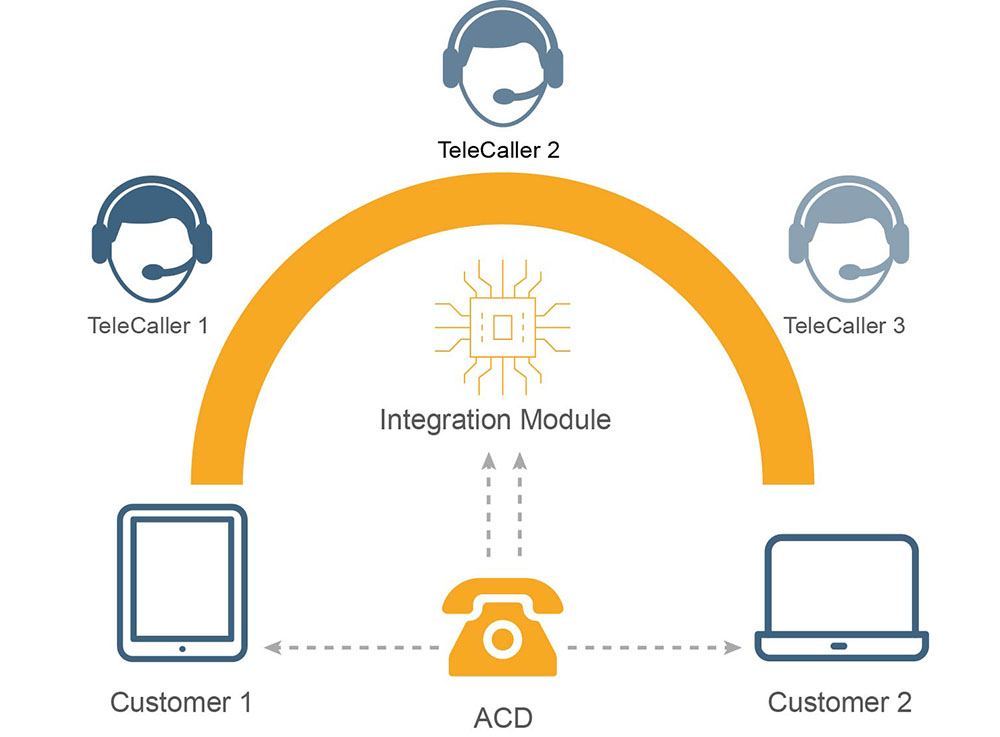
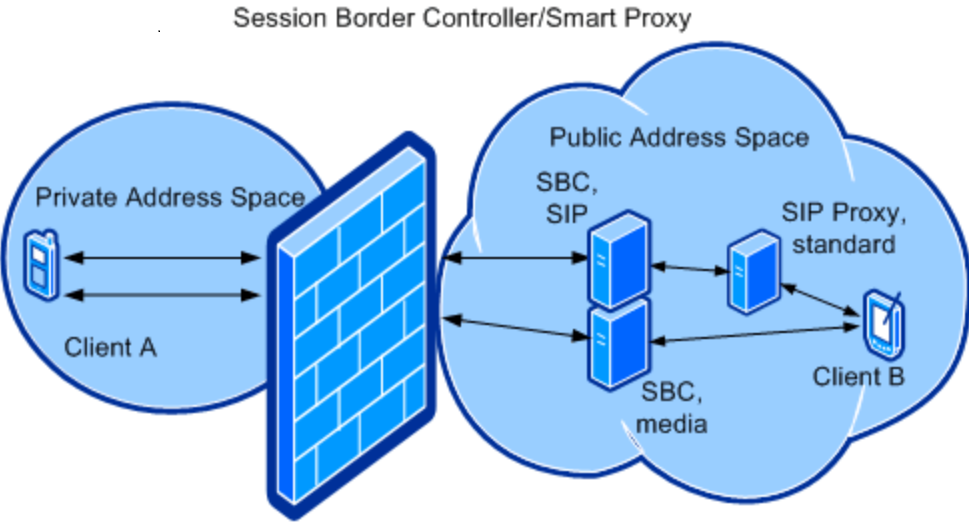
ASR(Automatic Speech Recognition) 自动语音识别,是一种使用计算机来识别人通过电话或麦克说话产生的语音信号的语音技术。作为专门的研究领域,ASR又是一门交叉学科,它与声学、语音学、语言学、数字信号处理理论、信息论、计算机科学等众多学科紧密相连。
在ASR中用到的最主要的技术是隐马尔可夫模型(Hidden Markov Model,HMM)。这种技术通过判断每个相邻小区的语音信号最可能是哪一个音素来识别单词,因为词汇表里的单词其实就是音素的组合。通过一种叫作Viterbi(一种动态规划算法,一般用于序列的译码)的搜索过程来决定最有可能是哪一个因素序列。搜索局限于词汇表的单词所对应的音素序列。ASR引擎的工作过程如图:
在ASR中用到的最主要的技术是隐马尔可夫模型(Hidden Markov Model,HMM)。这种技术通过判断每个相邻小区的语音信号最可能是哪一个音素来识别单词,因为词汇表里的单词其实就是音素的组合。通过一种叫作Viterbi(一种动态规划算法,一般用于序列的译码)的搜索过程来决定最有可能是哪一个因素序列。搜索局限于词汇表的单词所对应的音素序列。ASR引擎的工作过程如图:
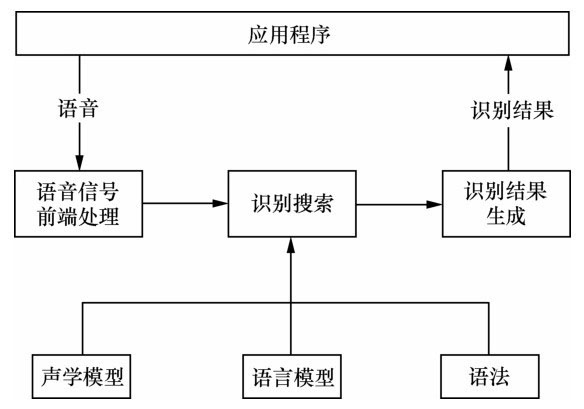
①前端语音处理:完成端点(话音的起始点和结束点)检测、降噪等。
②识别:根据声学模型、语言模型、语法进行识别。声学模型是语音识别系统中最关键的部分,它的作用就是前面提到的确定音素序列。语言模型是指语言中的一些规则或语法结构,是表现字或词上下文之间的统计模型。语言模型可以预测在句子中某个位置最可能出现的单词。语法对所有可能识别的语言进行描述,简单地说,语法告诉识别器应该听什么。语法可以用有向图来描述,图中的节点可以是一个单词或一个句子,如果识别成功,识别的结果将是图的一条路径。
③产生识别结果:识别结果按照一定的文本结构返回。
ASR分为两种:一种是独立于人的识别,即不管是谁,只要他说的话是一样的,识别结果都是相同的,它主要应用于人机交互,使用语言作为输入的优势是显而易见的,方便快捷;另一种是特定人的识别,又叫声纹校验,主要用来进行身份验证。在本文中讨论的ASR指的是第一种。
由于语音信号的多样性和复杂性,目前的语音识别系统只能在一定的限制条件下获得满意的性能,或者说只能应用于某些特定的场合。语音识别系统的性能大致取决于以下4类因素:识别词汇表的大小和语音的复杂性;语音信号的质量;单个说话人还是多说话人;硬件平台。
②识别:根据声学模型、语言模型、语法进行识别。声学模型是语音识别系统中最关键的部分,它的作用就是前面提到的确定音素序列。语言模型是指语言中的一些规则或语法结构,是表现字或词上下文之间的统计模型。语言模型可以预测在句子中某个位置最可能出现的单词。语法对所有可能识别的语言进行描述,简单地说,语法告诉识别器应该听什么。语法可以用有向图来描述,图中的节点可以是一个单词或一个句子,如果识别成功,识别的结果将是图的一条路径。
③产生识别结果:识别结果按照一定的文本结构返回。
ASR分为两种:一种是独立于人的识别,即不管是谁,只要他说的话是一样的,识别结果都是相同的,它主要应用于人机交互,使用语言作为输入的优势是显而易见的,方便快捷;另一种是特定人的识别,又叫声纹校验,主要用来进行身份验证。在本文中讨论的ASR指的是第一种。
由于语音信号的多样性和复杂性,目前的语音识别系统只能在一定的限制条件下获得满意的性能,或者说只能应用于某些特定的场合。语音识别系统的性能大致取决于以下4类因素:识别词汇表的大小和语音的复杂性;语音信号的质量;单个说话人还是多说话人;硬件平台。

语音识别技术的应用包括语音拨号、IVR语音导航、室内设备控制、语音文档检索、简单的听写数据录入等。语音识别技术与其他自然语言处理技术如机器翻译及语音合成技术相结合,可以构建出更加复杂的应用,例如语音到语音的翻译。 语音识别技术所涉及的领域包括:信号处理、模式识别、概率论和信息论、发声机理和听觉机理、人工智能等等。特别是在电话机器人中的IVR起作重要的作作